
July 14, 2014
John Beieler is a PhD student in the Department of Political Science at Pennsylvania State University and is currently a Summer Fellow at Caerus Associates. His research focuses on the generation and use of event data and the forecasting of political events.
Advances in technology and the popularity of individuals like Nate Silver have given rise to the exciting idea that political scientists can predict the future using statistical models. Despite the recent attention forecasting has received, it is still difficult to do well, especially for rare political events like the onset of mass atrocities. In order to address this challenge, the Early Warning Project has developed a system that combines statistical forecasting with crowd-sourced forecasts. This combination serves as the focus for this post.
Before turning to the combination of statistical and crowd-sourced forecasts, I want to focus on two issues with the forecasting of rare political events that directly relate to the work I do with data and forecasting. First, in order to make a statistical forecast, forecasters must acquire data, and that data is often hard to obtain for the types of events that political science forecasters tend to focus on, such as coups, civil war, and mass killing. When data is available, the quality and applicability are often questionable.
Second, even when forecasters are able to obtain good data, the events of interest are often extremely rare. For example, forecasters looking to anticipate onsets of mass atrocities might assemble thousands of data points representing over 50 years of history, yet actual onsets of mass atrocities would constitute only 1 to 2-percent of those observations. This means that there is little variance within the data, and where there is little variance, it’s extremely difficult for statistical models to find patterns that differentiate between cases in which an event will or will not occur. This lack of data is especially problematic because the underlying statistical models tend to matter less as the size of the dataset increases.
At this point it’s useful to take a step back and outline what the modeling process looks like for something like mass atrocities. First, using theories of why mass atrocities occur--whether based on elite ethnicity, regional instability, or combinations of several variables--forecasters attempt to assemble a dataset that accounts for those variables. Yet data availability often isn’t uniform across countries so forecasters often end up making sacrifices in the quality of the data they use. Next, a forecaster uses the data to develop a statistical model and can run various tests to see how well the model forecasts events it has not seen before.
This is where things get tricky when working with rare events. Even if the model achieves a high level of accuracy, it might not “predict” a single instance of the event, if predicting an event is taken to mean assigning a probability of its occurrence of 50-percent or higher. That’s because the actual events make up such a small percentage of the dataset that a model can predict no occurrences and still look highly accurate. With onsets of mass killing, for instance, a model that predicts that no onsets will ever occur will be right approximately 98-percent of the time.
Given this scenario, it’s clear that a more extensive examination of the model is necessary. Diving deeper into the output, the analyst might see that none of the observations had a predicted probability higher than 20-percent, and the statistical software she uses has a default value of 50-percent likelihood as the threshold for classifying a case as a predicted occurrence. Looking closer, however, she might find that the model was still able to provide some meaningful discrimination between countries. For example, if the vast majority of countries are forecast to have less than a 1-percent chance of an onset of mass atrocities, then those that have a 15 or even a 5-percent chance are evidently at higher risk and warrant further examination.
The work the Early Warning Project has done on statistically forecasting the onset of state-led mass killings mirrors the process described above. In the current risk assessments Myanmar has the highest statistical risk but still doesn’t rise above a 15-percent chance. If one were to simply use the default settings in many statistical forecasting models, as described above, this case wouldn’t be classified as having a potential onset. It’s also interesting to note the precipitous drop-off in likelihoods below 5-percent. This drop off provides the discrimination between cases that are highest risk and those that are at risk but might not warrant as much concern.

So where does that leave us? If the forecasts don’t cross a 50-percent threshold, are they still useful? How can we leverage that information? This is where the Early Warning Project’s crowd-sourced forecasts play an important and complementary role. The statistical models can provide some rough discrimination, or ranking, among cases. The expert knowledge gleaned from the opinion pool can provide further illumination and insight into the mechanics of a specific example. The statistical model points out cases that might be ripe for further attention from a dedicated group of forecasters or analysts who can then react to those assessments in a structured way through the opinion pool. By utilizing the judgment of experts, the Early Warning Project is able to generate highly dynamic and useful forecasts that are responsive not just to the statistical outputs, but also to current events and changes on the ground.
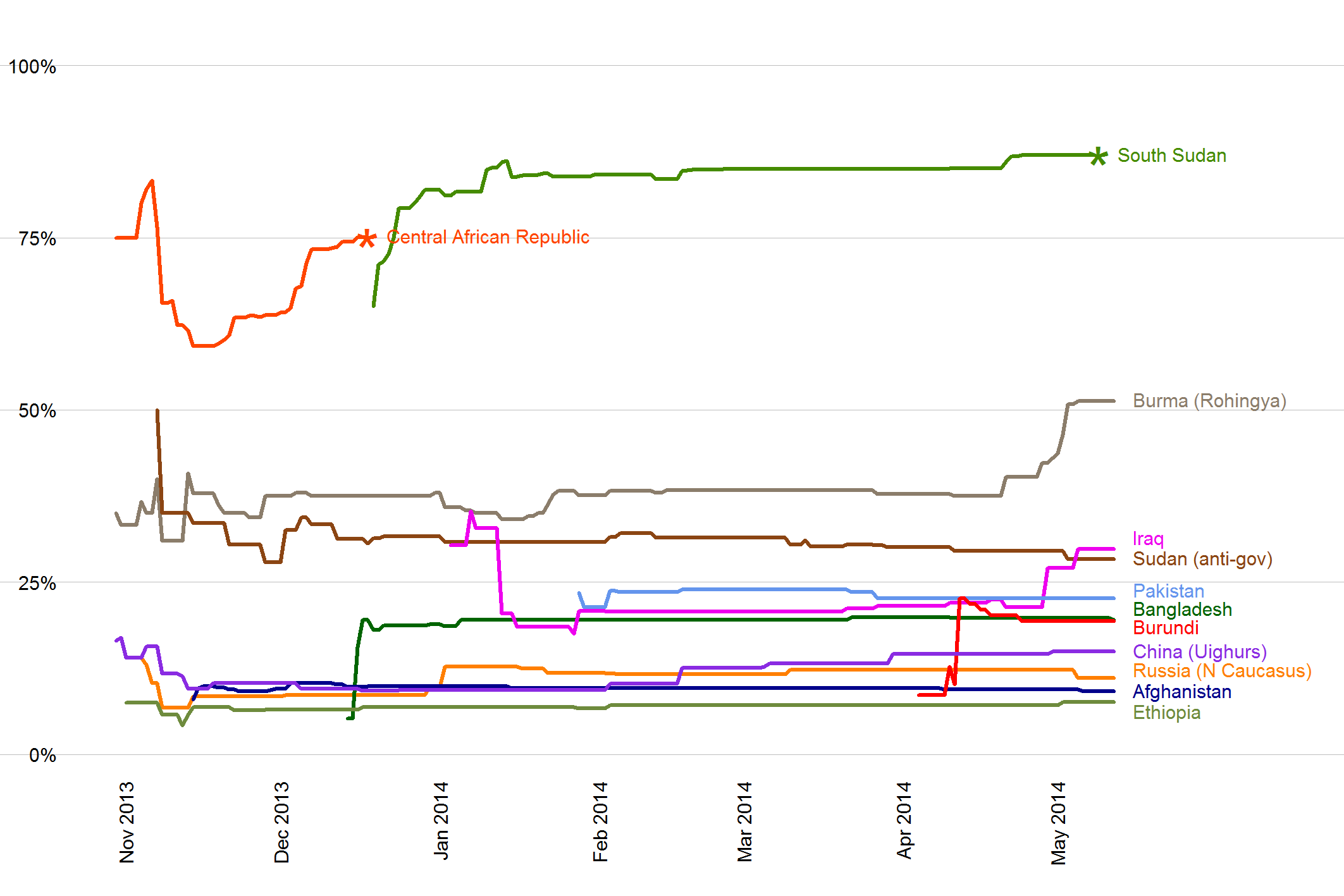
Crowd-Estimated Probabilities of Mass-Killing Onset Before 1 January 2015
As Jay notes in his blog post, the system seems to be working well so far:
In the six months since we started running this system, the two countries that have seen onsets of mass killing are both ones that our forecasters promptly and consistently put on the high side of 50 percent. Nearly all of the other cases, where mass killings haven’t yet occurred this year, have stuck on the low end of the scale.
Here, forecasters were able to provide accurate assessments of the situation in relevant countries. This is the powerful combination of the Early Warning Project: statistical models for the creation of a “watch list,” and a pool of experts who can further discriminate among those cases and can update their forecasts in real time.
View All Blog Posts